学习笔记:网页技术Ch10.搜素引擎和SEO
大家在google上搜索网站,很容易出现以下两种情况:
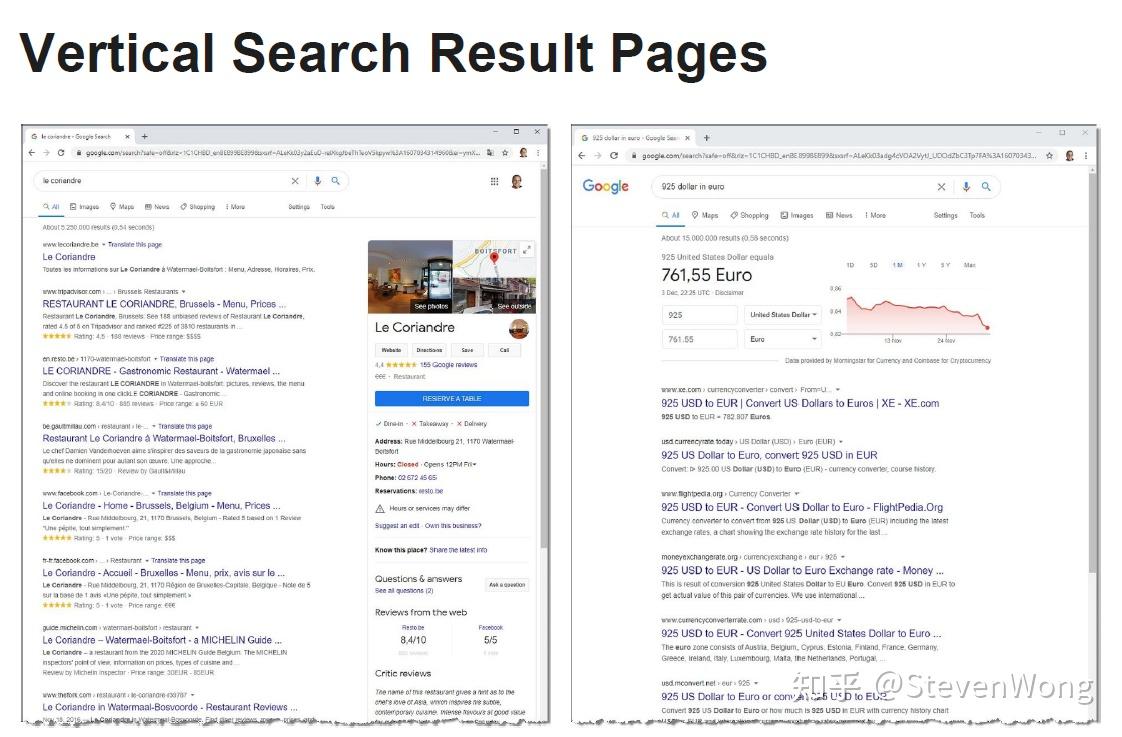
就是你搜索一个餐馆,谷歌会从自己的数据库里找一个放在旁边,这样的网页就是垂直搜索结果页面。
像搜索百度,出来的广告,就是网页的non-organic result
正常的内容就是organic result
下面来看看搜索引擎的历史:
Bush先提出了搜索引擎的概念
之后1990年出现了Archie,用于给FTP服务器上的文件加索引
后面出现了W3Catalog,是第一个网页搜索引擎,手动维护网页的镜像
之后是JumpStation,第一个有怕丑,索引,搜索的搜索引擎
后面就有很多不同的引擎了
但是他们普遍有两种搜索的方式:
- 全文搜索:用爬虫爬数据,然后搜索
- 主要用手动的方式维护网页的层级
既然搜索引擎出来了,那就要有能评价他们能力的指标,这里规定了几个:
precision:搜出来的我要的东西除以output
recall:搜出来得我要的东西除以总的我要的东西
之后把他们结合,就出来了F-score(harmonic mean)
下面介绍搜索引擎的原理:Boolean Model
其实就是把关键词放纵坐标,把网页放横坐标,搜到了就是1,没搜到就是0,
如果搜关键词,就调出来那一行,如果搜很多关键词,就作布尔运算,找1的输出
这样:
好处是能够提高搜索的效率,比较容易执行以及扩展
坏处就是没法rank,用户需要学这个语法进行搜索
所以这些旧的引擎要面对新的问题:
- 网页数量再一直增加
- 网页在一直更新
- 资源也会被修改
- 处理速度也是一个非常大的因素
下面介绍一下爬虫:

学习笔记:网页技术Ch10.搜素引擎和SEO
https://yiyuwang.be/2021/01/15/2021-01-15-344648110/