分布式原理:时间和同步
想象这么一个场景,你老板让你空手实现一个mapreduce的服务器集群,你写的时候发现,必须要所有的map结束之后才能让服务器开启reduce进程,而你操作的是一个服务器集群,有的服务器在欧洲,有的在亚洲,有的在月球。你该怎么办?

首先我们先来看看怎么让这些服务器上走的表对起来?
你就会说了:“啊!我找个标准时间来统一一下时间!咳咳,就用UTC吧。”
所以在开始运行的时候,你给所有的服务器都对好了时间,都采用你所在时区的UTC,运行起来了,very well,所有的服务器上的表都走的一样了,但是过了一段时间,你发现,由于地心引力(bushi)或者是小行星爆炸(bushi)的影响,月球上的时钟走得慢了,由于赤道的地心引力不同,离赤道近的服务器走的快了。 你非常忧虑。
由于地心影响表走的速度变快了:Clock Drift
由于你调表的时候粗心导致表的数字比平时大了:Clock Skew
于是,你决定,写一个对表的方法,每隔一段时间让他们对一下表!
由于你觉得他们应该是一个成熟的服务器,应该学会自己对表。于是你想出了两种方案:
1.你单独架设了一个无敌准的原子钟服务器,让每个服务器隔一段时间来找他对表。(External Synchronization)
2.你比较穷,买不起原子钟,于是你让那些服务器自力更生,自己内部讨论一下按照谁的表来走。(Internal Synchronization)
先来看看富裕阶级的解决方案,买一个原子钟,问题又来了,你发现,有的服务器在月球,有的在赤道,他们离你的距离有长有短,发电报还有延迟呢,别说对表这种精细工作了。
“那就测测来回需要多长时间!”
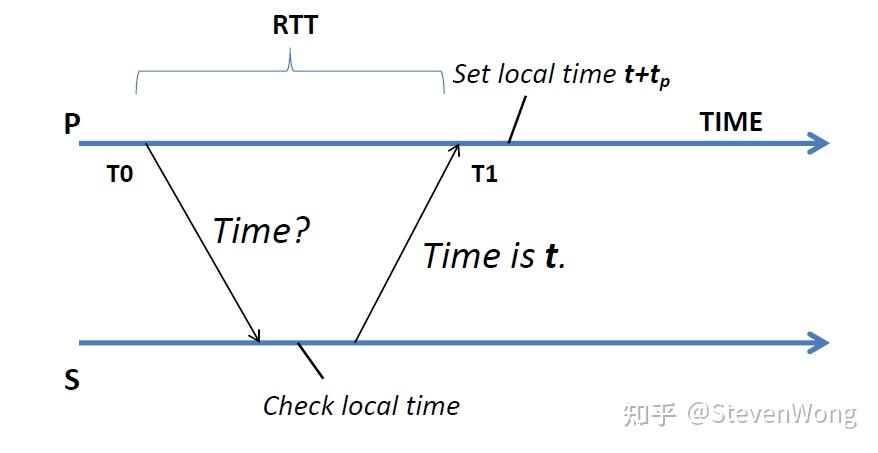
按照上图的模型一看,S是原子钟,P是服务器,P发一条请求问S时间,S处理一段时间发回来,P就把时间调城t+tp。那么问题就来了,tp怎么算呢?
如果你要求低,可以简单的认为: tp = (T1-T0)/2
但是,这不精准!首先来回的时间为什么是对称的,packet switch走的路一定一样吗?
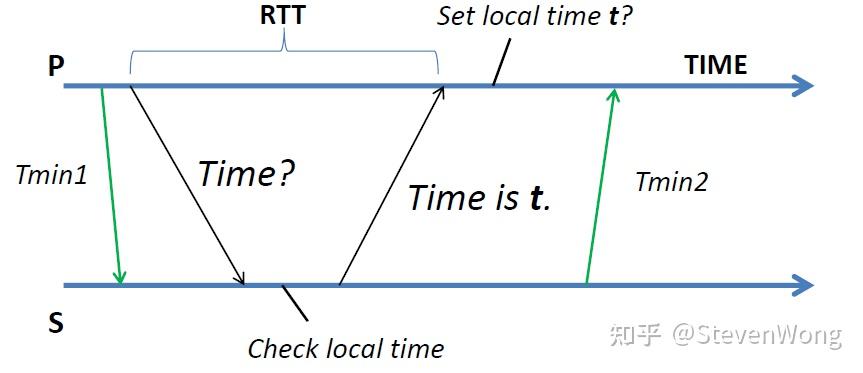
我们再建个模型来看,Tmin1是P到S的时间,Tmin2是S到P的时间。我们可以推测出,P收到的时间应该是介于t+Tmin2和t+(RTT-Tmin2)之间
那么取个平均值,就是t + (RTT-Tmin1+Tmin2)/2,也就是tp = (RTT-Tmin1+Tmin2)/2
**这种方法叫Cristian’s algorithm,**Cristian有教会的意思,教会肯定巨富啊,那么多赎罪券。所以这种方法就是富裕的方法。并且这种方法是用原子钟,原子钟可只作为一个回答时间的人,不会主要发起对话问别人的时间,因为它就是最准的。
有钱人的方法看完了,再看看穷人的方法:
穷人就盘算了,这些服务器肯定一开始是准时的,有些后面走的快了,有些后面走的慢了,我让他们平均一下不就行了!
于是,一个大胆的想法就出现了:虽然穷,但是牌面不能少,我也设置一个伪原子钟服务器,这个服务器不停的遍历问所有服务器的时间,然后把这些时间平均一下再发给他们。像极了玩剧本杀当凶手的你。你必须得先问好别人的时间是多少,然后自己计算一下再发给别人。
这种方法叫Berkeley algorithm。伯克利嘛,公立大学嘛,众所周知,美国的公立大学几乎都比私立大学穷,所以这种是穷人的方法。而这种方法的原子钟比较卑微,得先问别人,因为它自己啥也不知道。
费劲千辛万苦,你终于实现了所有服务器的时钟同步,现在出现了一个问题,你需要给进程规定顺序,得先搞完map了才能搞reduce啊,主要任务不能忘!
为了书写方便,你简单变化了一下js的箭头函数,a → b 就是 a happens before b。
你画了一个任务图,里面的箭头表示服务器之间沟通信息。
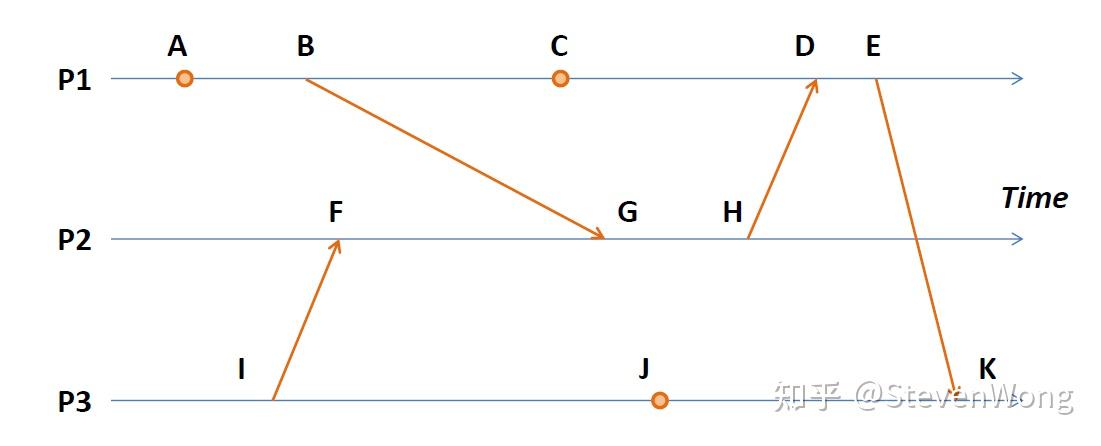
于是你快速写出了。
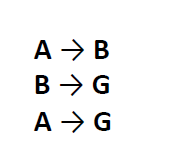
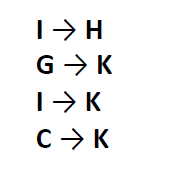
但是这是凭借你聪明的大脑和灵力的双眼得出的答案,服务器这么笨,是不可能做出来的。于是你打算写一种算法帮助服务器完成这项任务。
就用时间戳吧,时间戳大的发生在时间戳小的之后!
于是你这么规定:
每个进程时间戳初始是0,有事情发生就++
如果两个服务器相互沟通,那么就先给发送的服务器++,然后传递信息之后再++,和本地++的时间作对比,选大的。
写成代码:
1 | |

经过这么一搞,你得到了:
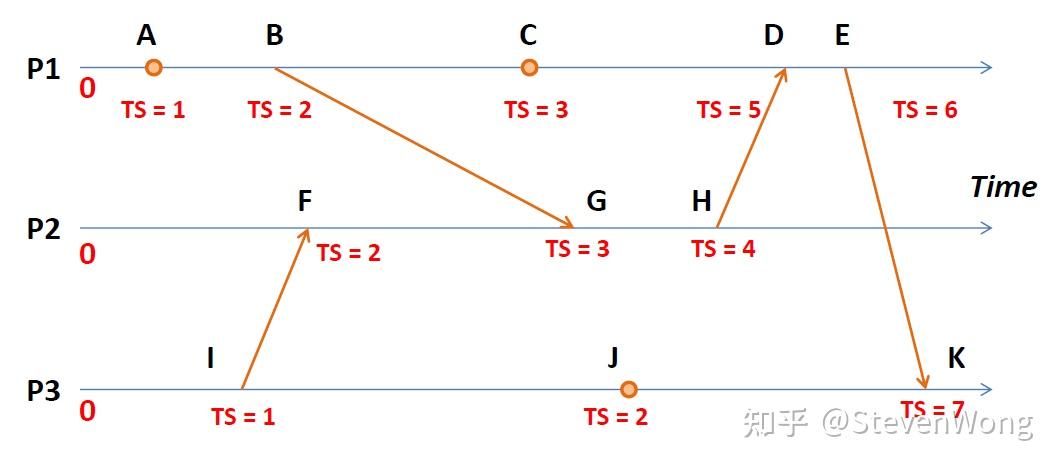
你发现,好像大部分按照时间戳来算的是对的,但是对于C和I,C和J来看,貌似不大对
这种方法叫Lamport Timestamps,根据它的推导:
如果事件 A 在事件 B 之前发生,(叫做happened-before,表示为A→B),那么事件 A 的时间戳一定小于事件 B。
你还推出来了:
如果C(A)<=C(B) ,那么事件 B 是绝对不可能发生在事件 A 之前。
以及: 如果事件 A 和 事件 B 的时间戳相同,则它们是并行或独立的
你想了一下,发现,这不是脱了裤子放屁嘛,我都知道了发生的先后顺序,还需要去验证时间戳干嘛?
于是你查阅资料,发现了最终的解决方案:Vector Timestamps
大体的思路是这样的,每个服务器都有一个整体的时间戳Vector,自己行上出现了事件给自己位置上的++,如果发生了信息传播,传播者先给自己++,然后给收者的位置也++,然后遍历两个vector,都取大的。
写成JAVA代码:
1 | |
于是你得到了:
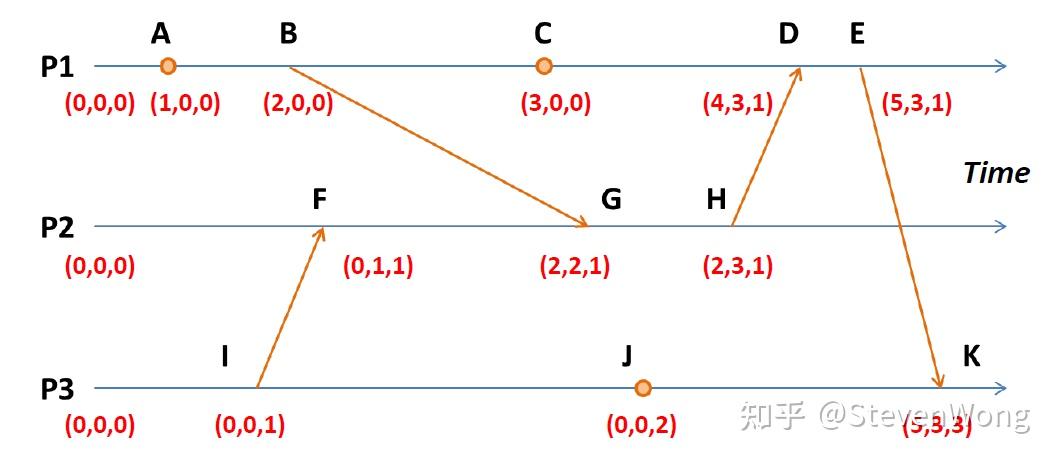
对比三个位置的数,如果都大,说明这个事件发生的比较晚:

如果有大有小,说明并发:
