学习笔记:计算机组成原理Ch1.总体介绍
先来看一个典型的计算机结构:
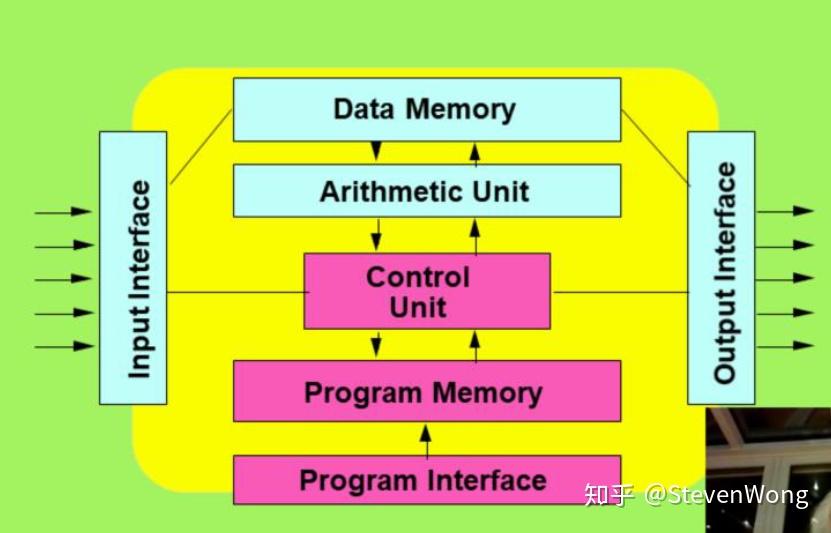
先来看Data Memory:
可以把他看作一个抽屉架,如果我要改变其中一个抽屉里的东西,必定会清除掉原来抽屉的东西。
之后再看Arithmetic unit:
这里会提到有关指令:Instruction Format
有两种:

OPC是Operation Code,OP是operation,RES是result,NEXT就是NEXT
就是一个约定俗成的格式罢了。
这里再介绍几个代号:
ND:the information of SC
SC:secret code
KFL:Keyboard Flag,0是没有,1是有
KDA:键盘输入的东西
DDA:输出
就像大家想的那样,计算机只会识别0或者1,那么也就意味着,指令必须翻译成0或者1的语言,这就出现了一个特殊的程序assembler。
它可以把Low Level Language 翻译成 机器识别的machine language。
补充:machine language 写成的代码一般叫做 Object Code
而程序员写的代码叫source code—src
下面介绍像过家家一样的assembler的操作步骤:
- 加载assembler
- 一行一行翻译
- 把翻译好的OC放入内存加载
- 执行
颇有一种“把大象放进冰箱需要几步”的感觉
那么写给assembler的语言就叫做assembly language,下面介绍几个特性:
- 它保存了变量、接口等东西的符号名字
- 操作通常也都有一个唤醒(evoke)用的名字
- 会出现一些无意义的操作名,比如“结束”“开始”,这种叫做Pseudo Instruction
于是问题就来了,在之前提到过,assembler是一行一行翻译,那么我们后面定义的操作标签,如果在前面调用了该咋整?
两种解决方案:
- one pass:扫描到不认识的东西,先留下memory space,之后填上
- two pass:我直接扫描翻译两遍
之后,介绍一个定义Macro(宏):
其实就是因为懒,有一些重复性的东西,用一个代号代替,以后就直接写代号。

那这个不就是函数嘛?
-其实不是,函数更加高级
Function VS Macros:

理解:每一次Macros其实就是翻译的时候,给你补上你没写的
而函数是直接跳到函数那调用。
再介绍Linker的概念:一个程序如果是由不同的文件组成,就需要一个连接用的Program,就是linker
怎么操作的呢?
每一个部分分别进行翻译,再运行之前组合在一起。
那么就需要一个定位的代码(relocatable object code)

下面介绍两种翻译方式:
Compilers VS Interpreters:
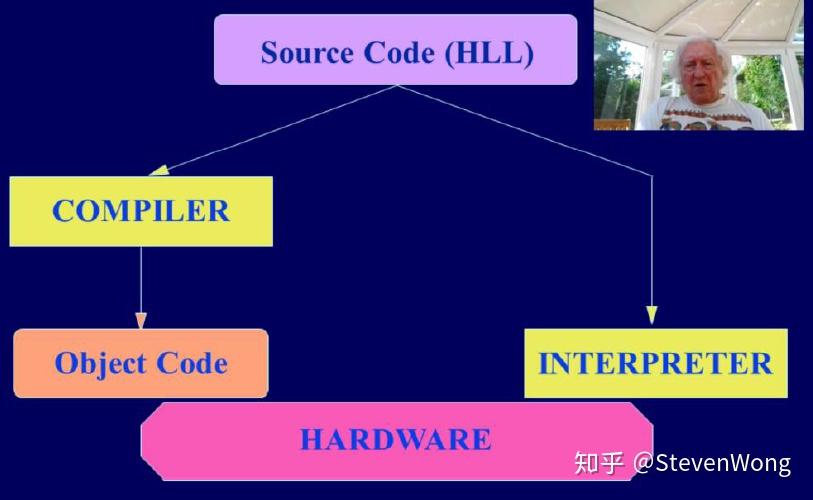
不同于okmpilers的逐行翻译,最后生成一个OC,Interpreter是真正贯彻了逐行翻译逐行运行。
研究一下两者的内部构造,其实是差不多的:
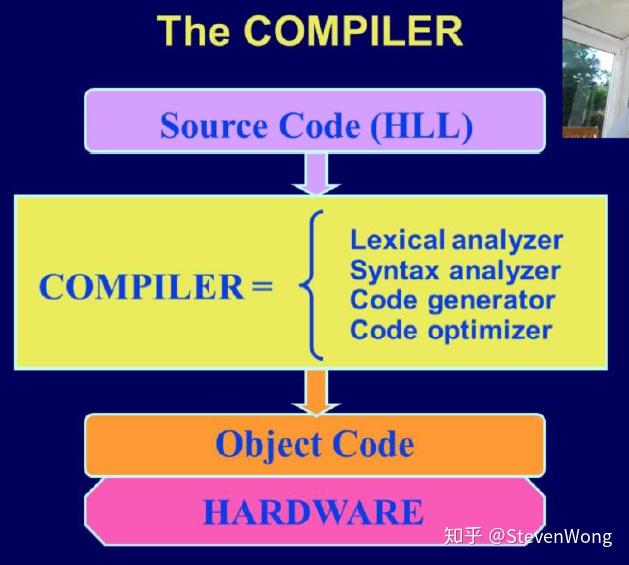
Lexical Analyser:检查字符的错误
Syntax Analyser:检查语法的错误