分布式原理:MapReduce的用法以及环境
MapReduce的用法:
MapReduce是最常用的分布式计算框架,他源于函数式编程语言的Map和Reduce方法。
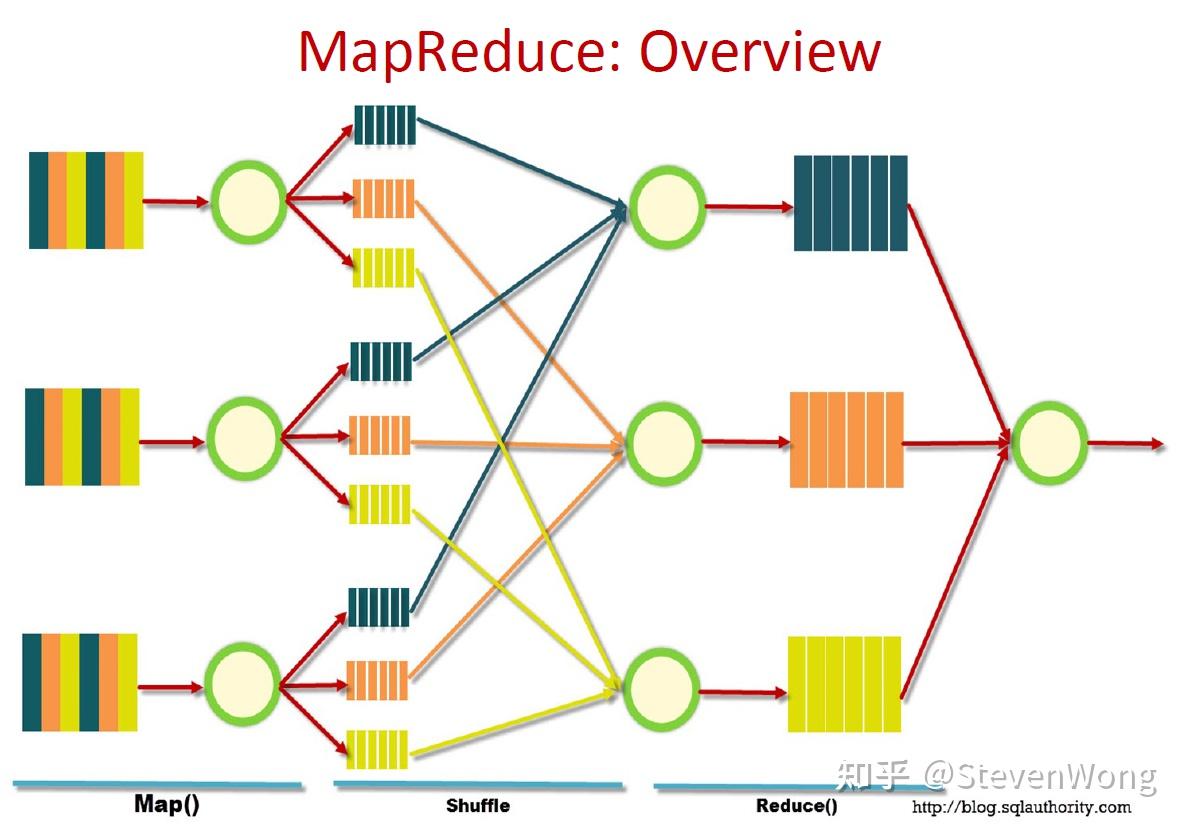
简单来说,map就是并行运算给所有的item打标签,reduce是把这些标签汇总的过程。
步骤:
1. 由系统一行一行读取信息并输入Map函数
2. Map处理kv键值对,经过一些算法之后输出一个intermediate kv键值对
3. (可选) 由combiner对本地的map做的intermediate kv进行处理,输出给reduce
4. reduce拿到intermediate kv键值对,进行最后的处理输出,值得一提的是,此处同一个reduce process会拿到同一个key的所有value进行处理输出
宏观概念有了,现在来讲一下细节的问题:
如何让key一样的kv键值对group在一起呢? 用hash值
如果key很分散,需要的reduce process就会很多,为了效率,就需要partition函数,一般是这么解决的

combiner和reducer有什么区别?
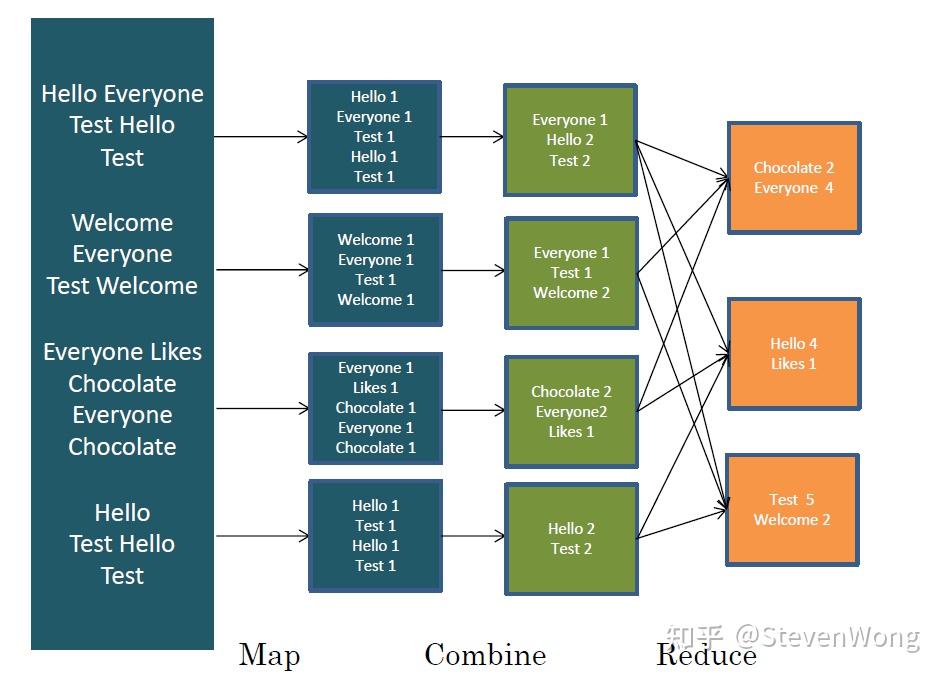
combiner可以被看做是local的reducer,何为local,就是指的和map在同一个环境下运行,map处理完它接着处理,但是combiner处理之后的结果仍然是一个intermediate kv,而reducer处理完的结果是可以输出的output file
具体关系可以看下图:
MapReduce的环境:
前面说完了如何使用,下面就要说说它后台的一些实现方式,也就是mapreduce是在一个什么样的环境下运行的。
我们从顶层往下想,这个环境需要做一些什么事情:
首先,读取数据的时候是一行一行放进map里的,那么就需要我们的环境能够划分(partition)输入的东西
然后,map的操作应该是在一堆分布式机器上同时进行的,那么我们的环境就应该能够安排(Schedule)这些进程的工作
之后,我们需要把map输出的kv汇总,并按照key来分组传入reducer,所以环境应该能够实现分组(group by key)
既然是分布式环境,我们的环境还应该能够handle failure以及管理这些多机器的通信
下面我们分步介绍上面这些是怎么做到的:
划分输入的东西比较简单,就实现一个读函数就可以。
安排map的工作也比较容易,因为map的工作本身就是很独立的,完全可以无脑并行运行(利用YARN)
之后我们用partition function就可以实现group by key并分配给reducer任务,之前介绍过直接无脑hash的方法
插一嘴,我们看一下各自的input output的存放位置:

好了,现在可以讲一下如何分配进程以及运算资源(CPU+memory)
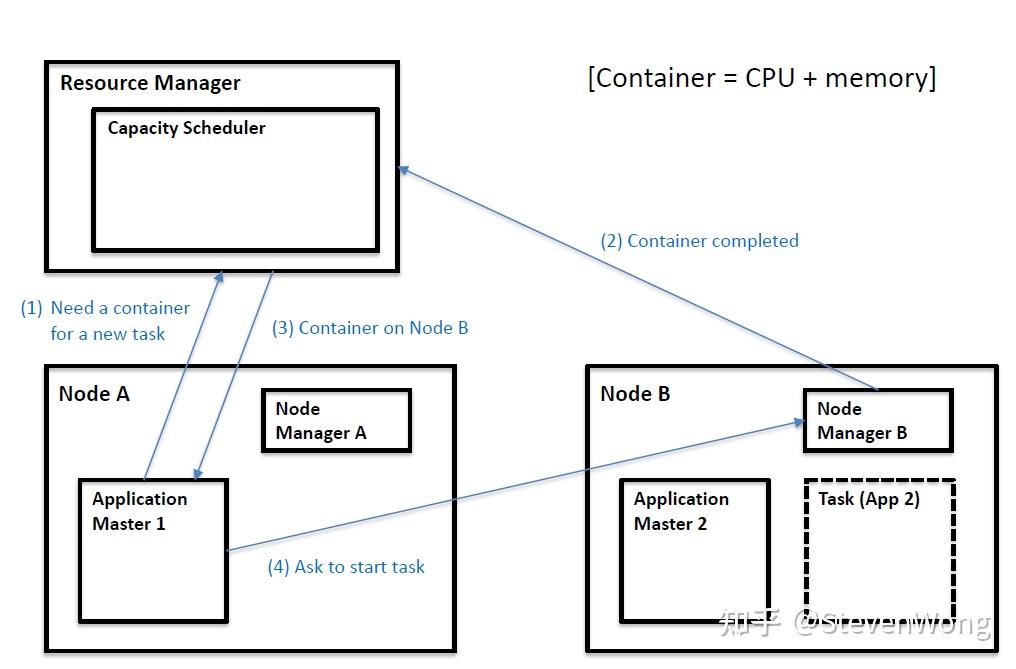
YARN架构
主要分成:
RM: ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
AM:每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话**山不过来,我就过去。**大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
NM:NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
如何控制failure?
主要通过心跳机制,NM会发送heartbeat给RM,AM也会发送heartbeat给RM,NM同时会track所有在当地server运行的程序,如果挂了,就记录并重启。
为了发heartbeat而发就很浪费资源,所以一般heartbeat会携带(piggyback)一些信息,例如container request。
在监控的过程中还有可能出现,特别拉垮带不动的server,如果遇到AM就会复制task放在别的地方运行。
下面看一下总结;
