分布式原理:Gossip 协议
之前介绍过分布式编程的方法:MapReduce,那么在分布式系统中,肯定不能用TCP/UDP进行沟通,需要有分布式特点的协议,也就是我们的Gossip协议!
。。要不先来看看如果用TCP/UDP应该怎么沟通?
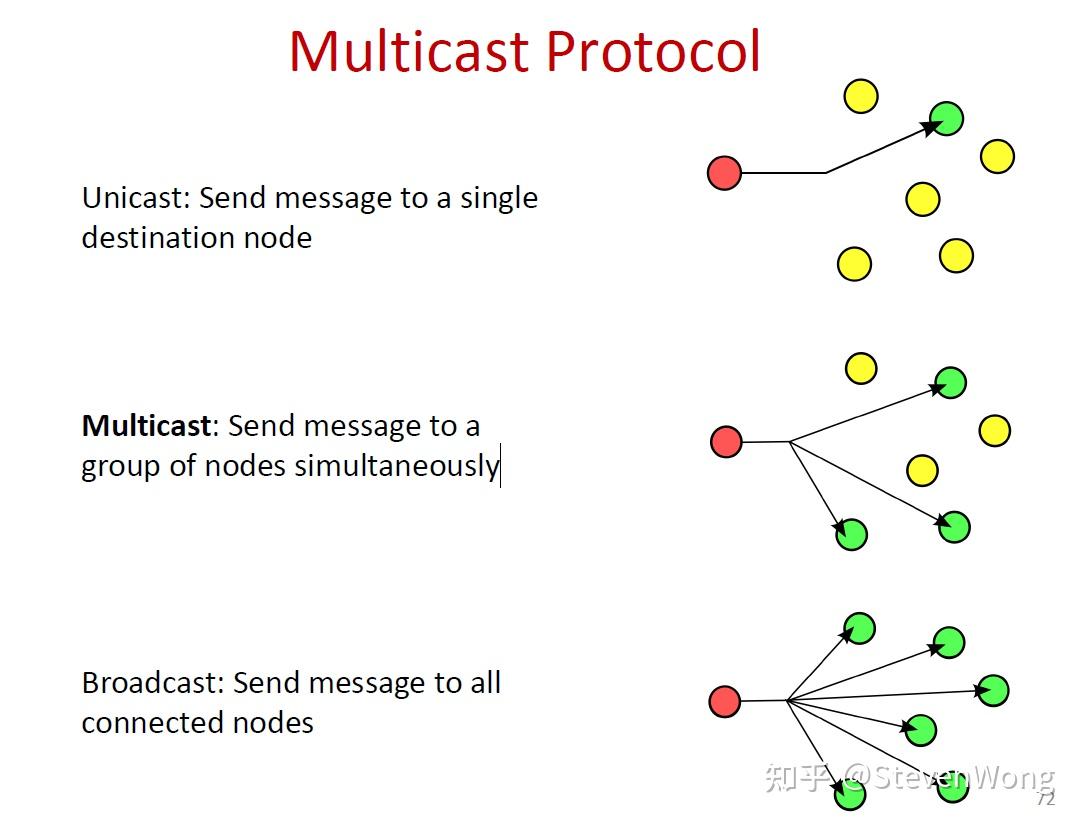
如果要跟服务器沟通,就要发送信息,TCP/UDP都是点对点的发送,可以分为以下三种情况:
我们先来想一想,如果你想要设计一个分布式的沟通协议,应该满足什么要求:
- 要能够容错,也就是要有可靠性
- 要能够轻易拓展
再来看看上面这些multicast的方式,很明显,如果发送的node挂了,信息就无了,而且传输的时候同意丢包,真的要这么发的话,还得TCP三次握手,但是,这样维系session是不是成本太高了,然后一次发送,要等待最后一个最慢的node接收才算结束,是不是又不合适。
就有人想了,参考古代帝制,我们设计一个传话系统,整一个node二叉树进行传话!
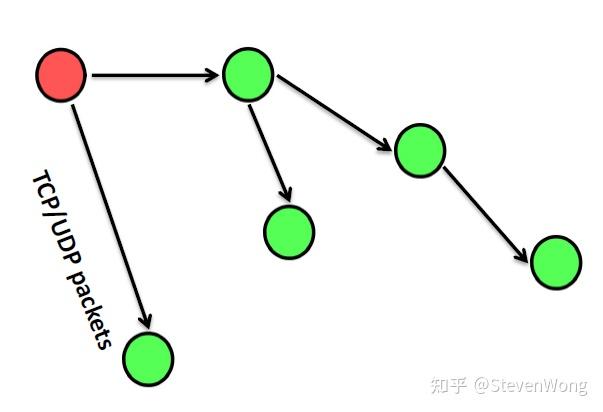
然后设计的时候参考TCP,我们用ack和nak表示接收的node收到packets与否
插一嘴,欸!是不是计算机网络里学过一个类似的在IP层的协议:
IGMP是Internet Group Management Ptotocol的简称,被称为互联网组管理协议,是TCP/IP协议族中负责IPV4组播成员管理的协议。
然后只需要这个二叉树能实现:
Scalable Reliable Multicast (SRM) 可扩展的可靠组播:
就是一个包在树分叉的时候也复制发送,用NAKs来实现可靠性(只有没收到才给我说一声,收到了别吭声),但是如果同时出来一堆NAKs,就是NAK地狱,我们可以给每个node设置延时,你没收到别立刻回NAKs,等一阵再说。
Reliable Multicast Transport Protocol (RMTP) 可靠的多播传输协议:
分级汇报,你的下级没收到信息,你汇总一下发给我就行了,别嗷嗷全把东西发给我。
感觉是不是很无力,所以我们需要一个分布式专用的协议,Gossip:
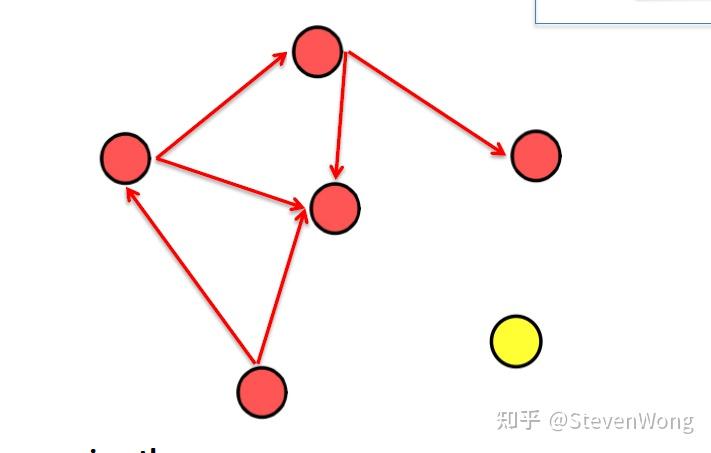
就像传播绯闻一样,一传二,二传四,四传千千万,那么就有问题了,如何保证可靠性?
我们不保证可靠性!就像新冠一样,我传播了之后它就一直传播,直到把所有人都感染。
Gossip 的特点(优势)
1)扩展性
网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
2)容错
网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
3)去中心化
Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
4)一致性收敛
Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
主要有三种gossip:
- Push: 节点 A 将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据
- Pull:A 仅将数据 key, version 推送给 B,B 将本地比 A 新的数据(Key, value, version)推送给 A,A 更新本地
- Push/Pull:与 Pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 则更新本地
