分布式原理:错误探测和成员表
错误检测
一个可靠的系统必须具备下面四点:

然后错误又分为下面三种,理论性的东西而已

那么在分布式系统里,我们怎么防止错误的出现呢(failure masking)
- 信息冗余,比如出错的概率是1%,我把信息变多了,正确信息出错的概率就小了,我加一堆冗余的信息
- 次数的重复,多发几次
- 物理的重复,多弄几个设备存
成员表
上面说了那么多,其实错误检测主要是为了控制一个成员表,成员表顾名思义,就是维系一个分布式系统有多少成员的列表,或者说,有多少在线用户(没有崩的)列表。
那么就需要注意,1.怎么检测有没有崩 2.怎么传播(dissemination)这个列表
先来看看怎么检测,我们要检测,就是如果有人崩了,必须得有人知道,所以可是宁错杀一万,不留一个坏的,所以,它可以容忍假阳性,但是不能容忍没有检测出来。

很明显我们可以看出,完备性和准确性是不能同时存在的,也就是你不能要求它做的又对又全,能全对就不能全做完,能全做完就不保证全对。这里选择了全做完!
Completeness – always guaranteed
所以我们由上面的条件诞生了。。。heartbeat检测,其实这玩意早就在用了。。。
维系一个seq,隔一段时间就++
传播方式当然是选择,Gossip一样的传播,毕竟是分布式系统嘛!
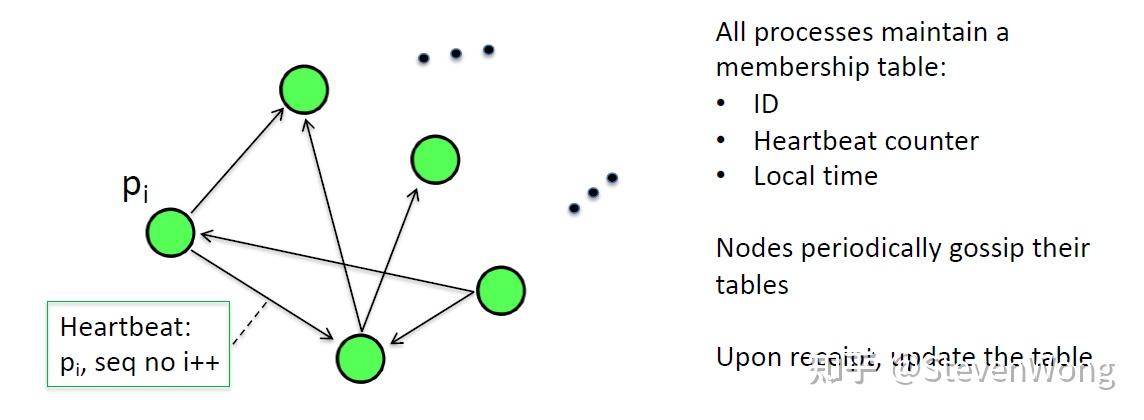
每个node维系一个table,有所有的在线node 的ID,seq,local time
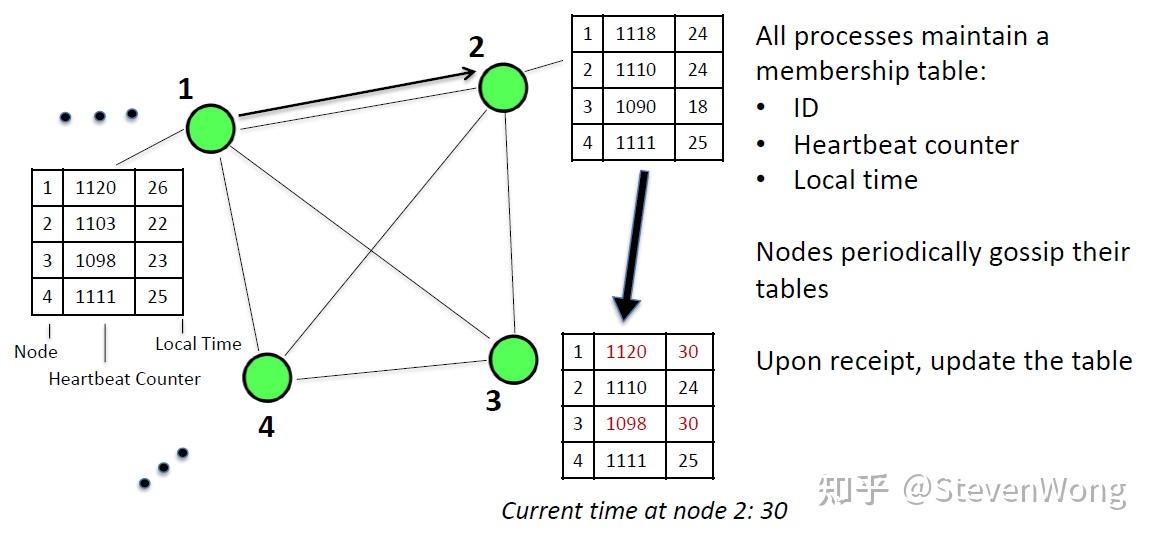
如何更新呢?记住口诀,只更新大的时间晚的,超时剔除
什么意思呢?就是说,当一个node发送给你一个table,你先看一下这两个table的所有seq有没有差别,找到有差别的,然后看看时间,如果有差别的,只更新大的且时间晚的,如下图所示
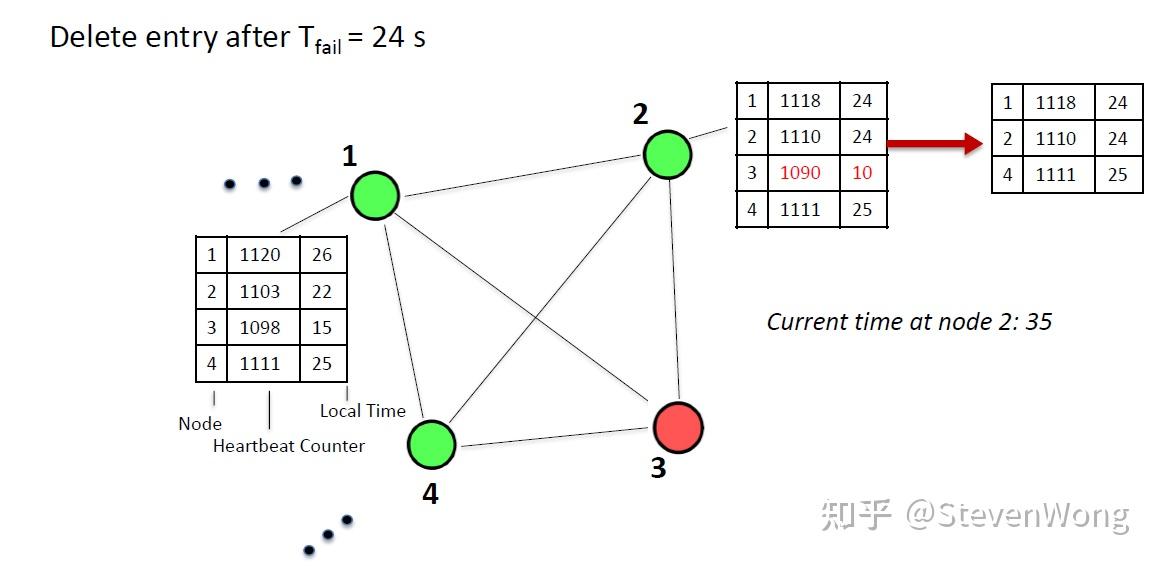
并且我们设置一个超时时间,当table里的localtime+超时时间超过了本地的时间时候,将这个node剔除!
如果从别的node的table又发现了它,那也可以将他复活(incarnation)
那么问题就来了,如果一个node真的死了,但是一定有node记得他,那么这个node就反复发送死去的它的信息,它就永远活在了这个系统里,这可不行,于是我们还需要设计一个Tclean,超过这个时间,就必须在所有node中删除!
后面我们又想,如果这个分布式系统特别大,每个node维系的table就会特别大,每次发送这么大的表那也不是一件好事,于是SWIM协议就诞生。
SWIM:
Scalable Weakly-consistent Infection-style Membership Protocol(SWIM),可扩展的弱一致的感染式成员协议。简单来说,就是每次heartbeat不发送table了,只给对应的节点发送ping,如果有反应(ack)就更新自己心中的表。
失效检测:
首先就是直接发送ping,没有回复可以继续发给附近的节点,让他们帮忙问问这个node有没有死
传播机制:
Gossip!!
在失效检测中,还可以提供权重系统,也就是怀疑系统(suspision system)
如果一个node被判定失效(ping不出来)之后,我们首先先将他的状态改成suspicion,怀疑它死了,如果过一段时间,它又ping的出来了,我们再让他复活,如果timeout,就宣布它的死亡
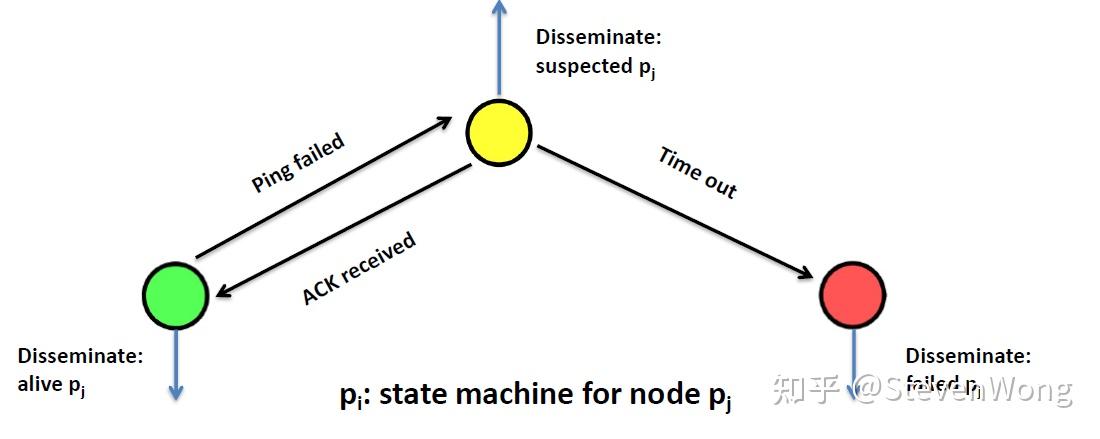
在此我们又引入了复活机制(incarnation)
每次从suspicion到active的时候给这个人的incarnation数目++(初始都是0)
然后设置一个override机制
